
By Lin Chen, Cambia AI director of Engineering
Sometimes when a team is building AI applications, we lack the proper data needed to train machine learning models. In July, our AI team hosted a Cambia AI Meetup in Portland with focus on cold starting a conversational interface. I want to shed some light on our journey and how we overcame this when we built a conversational AI solution at Cambia.
We all know healthcare is complicated but there are several frequently-asked questions people have that could be answered easily. For example, how to get a temporary insurance card or getting help finding a primary care provider (PCP). We started this journey by using conversational AI through a chatbot to answer routine questions, automatically. Our ultimate goal is to improve the consumer experience, but we started by building a chatbot for our customer service teams.
Building a chatbot is systems engineering. It requires a multidisciplinary effort to make it happen, such as software engineering, machine learning, natural language processing and data engineering. While we needed to bootstrap from multiple fronts, today we’re focusing on how we bootstrapped the chatbot from a data perspective.
In kicking this off we started out with three data sets to work with – one based on 500,000 scrubbed chat conversations from our customer service team, a generated synthetic data set used to train machine learning models and a third coming from production logs.
For the first, we didn’t have any labeled data to train our machine learning models. Our approach was to build a working version of the chatbot and continue to improve it with interactions we collected through our customer service professionals using it. See figure 1 for the overall approach.
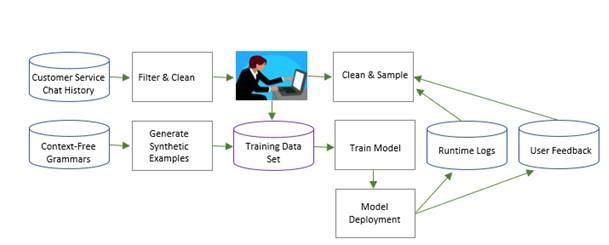
Figure 1. Continuous Data Collecting
We had seven years’ worth of nearly 500,000 conversations – via our health plan customer service chat conversations – that served as our first dataset. We cleansed the data then ran topic modeling and clustering. The results were used for two purposes:
- Find the relevant examples for a given skill to understand how a similar question was asked by a human.
- Extract the question-and-answer pairs for the skill to give answers for these frequently asked questions.
We had a team serve as data annotators to label the data. Since we followed the standard natural language understanding (NLU) approach, there were two primary annotation tasks: intent classification and slot filling. Intent classification annotation is about categorizing sentences into given categories. Slot filling annotation is about extracting phrases and labeling them with an information category, e.g. label “foot doctor” in “Find a foot doctor in Seattle” as a specialty.
The second dataset used to train machine learning models supporting the chatbot was the generated synthetic data. We didn’t have enough real examples to train meaningful models. Our approach was to use real examples as seeds, then build Context-Free Grammars (CFGs) to generate more examples. Figure 2 shows one such CFG example.
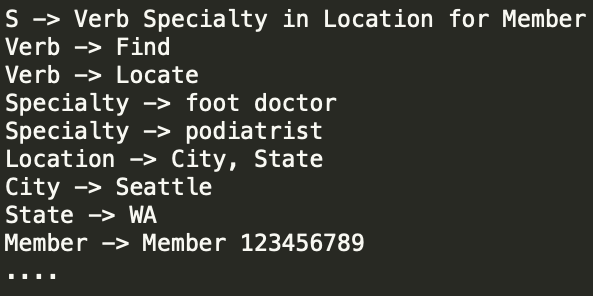
Figure 2. Context-Free Grammars Example
The main advantage of using CFGs to generate examples was that it did not require any annotations for either intents or slots, so we could get several examples without human annotations. Moreover, the CFGs could be reused. However, the generated dataset didn’t have enough variety.
The third dataset came from the production logs. We logged what was asked to the system and the run-time machine learning classification results. In the chatbot user interface, we also built a mechanism to allow our customer service professionals to give feedback on their experience using the chatbot. With the combination of the logs and feedback, we were able to automatically collect examples that enhanced our training dataset. While only a small portion of users gave us feedback on the results, we sampled examples from the production log, focusing on the examples where the production machine learning models had lower confidence. The sampled examples were sent to our team of annotators to check and provide accurate labels.
As a result of this work, we improved and expanded out chatbot skills, including:
- Provider search, e.g., Find in network foot doctors in Seattle, WA.
- Finding in-network providers, e.g., Is Dr. John Smith in network?
- Find out if a specific category of benefits is available, e.g. What are my dental benefits?
- Find answers for frequently asked questions, e.g. Can I get a replacement insurance card?
- Find insurance term definitions, e.g. What does deductible mean?
- Find medical term definitions, e.g. What is immunotherapy?
- Search and find facts about a specific drug, e.g., What is the delivery method of minocycline?
To summarize, cold start is a common problem for machine learning projects. We shared how we built a process to address the issue. Within such a set-up, we were able to grow the chatbot’s skills to many. In addition to the chat interface, we are piloting other conversational interfaces using the same approach – with the ultimate goal of a better experience for health care consumers. To learn more about Cambia, visit us here.
© 2019 Cambia Health Solutions, Inc.